Convolution types: transposed convolution and dilated convolution
Depthwise separable convolution
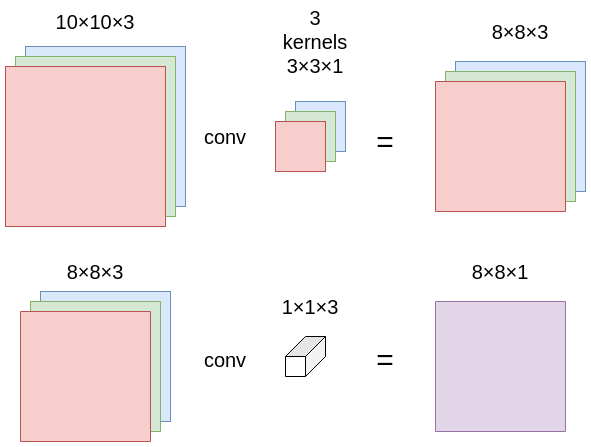
As example we take an $10\times 10\times 3$ image. Our goal is to convolve it with a $3 \times 3$ filters (with no padding and a $stride = 1$) and output $8 \times 8 \times 32$ feature map.
Depthwise separable convolution is separated into two parts:
- depthwise convolution applies a single filter per channel: $10\times 10\times 3 \rightarrow 8 \times 8 \times 3$
- pointwise convolution is $1\times1\times d$, it iterates through every single point. $d$ is the number of input channels. In the example above $d = 3$ and we get: $8 \times 8 \times 3 \rightarrow 8 \times 8 \times 1$.
Multiplication efficiency:
- conv: $32 \times 3 \times 3 \times 3 \times 8 \times 8$
- separable conv: $3 \times 3 \times 3 \times 8 \times 8 + 32 \times 1 \times 1 \times 3 \times 8 \times 8$